SEO for Travel: The Complete Guide To On-Page Optimisation For 2020-21
Complete Guide To On-Page SEO
On-page SEO (also known as on-page SEO) involves improvements to your website content in order to rank higher and earn more relevant traffic from search engines.
This can refer to optimising both the content, the speed and the HTML source code of a page.
On-page SEO for Travel is about enabling search engines and people to clearly and quickly understand what a page is about, and which are the most appropriate keywords.
The objective is to ensure that each page is targeted to a search query or queries (keyword or set of keywords), and that the page is worthy of ranking prominently within the relevant search engine results page (SERP).
SEO Keywords
Dress your Keywords for Success
Having the right dress code will open the door to strong ranks in search engines. From keyword research to content writing, the process is a fine art, where quality comes before quantity.
It’s not about how much content you’ve got on your website, but how good it is considered to be in the opinion of search engines. It’s rather straightforward, there is no reason to publish content if no one will find it useful.
The aim is to provide useful and relevant information based on the users search query.

This is why keyword research is so important.
Each page needs to provide clear guidance to search engines as to the keyword it is targeting.
For each of your pages, ask yourself how relevant the content is to the user intent behind the search query.
What is important is relevance.
Read our guide on using keyword research tools to find the right keywords for your business.
Quality keyword research and selection is an ever increasingly important skill for digital marketers.
Marketers need to know how to develop a good keyword list for PPC and SEO.
Keyword research is crucial to understand what topics and keyword groups should be the focus of blog content.
- Firstly, create a seed list of starting terms
- Then, expand your list by using keyword research tools
- Lastly, refine your list with competitive research.
What keyword types are available to you:
1. Brand name terms
It’s OK to build on your brand name success and use it further.
People who are familiar with your brand already are the easiest of all to convert.
2. Product terms
They describe the product type, what it does, or what problems it solves.
3. Competitor terms
Earlier in the life of paid search marketing, this type of terms was second only after brand terms for conversion rate and CPA efficiency.
4. Substitute product terms
Terms that can be used as an alternative of your product, e.g. instead of “pens”, optimize for “pencils”.
5. Complementary product terms
Terms for products that complement you product, ie. wireless laptop mice if you sell laptops.
6. Audience terms
This vast category covers all sorts of terms that your target audience might be searching for.
As this category’s impression volume is huge, there is always space for your to experiment with and gain a bigger audience.
Keyword Stuffing
Keyword stuffing is actually as old as SEO itself.
In fact, back in those glorious days when Google was an infant trying to step on AltaVista’s footprints, keyword stuffing was a great way to perform well in SEO!
All you had to do was to stuff hundreds of keywords that made up a text with no meaning at all.
To overcome the bad user experience, the keyword-stuffed text was often kept hidden from the human eye.
For instance the font colour was the same with the background, or the text was hidden using CSS (zero font size) or it was positioned outside the visible screen area or even behind an image.
Nowadays search engines have become far more sophisticated and they are equipped with filters and algorithms that can very easily report keyword stuffing.
Beware, if they catch you stuffing your ranking will plummet.
If you have to use non-visible text in your page remember to modify your code so that you use the alt to describe images, <noscript> tag for JavaScript content and descriptive text about a video in HTML.
Instead of keyword stuffing, put your effort to creating rich, original and useful quality content.
Use specialised keywords—long tail keywords—and include only those that are closely related to the topic of the web page. Add new and original content to your site and don’t repeat yourself.
Search engines are becoming ever more sophisticated.
They are now able to extract meaning from the use of synonyms, the frequency of specific word combinations and many other factors; however the importance of ensuring that page titles and headers are appropriate has not diminished.
Titles & Headers
Headers – H1, H2 etc
What are heading tags and why are so important in SEO?
An important factor to remember is that all search engines pay attention to the page titles and headers. Besides the obvious visual effects, titles and headers comprise a very important part in effective keyword targeting.
Text has structure, something denoted by the title, the subtitles, the bold parts and the italics. Web pages follow the same patterns with a bit different industrialisation.
Here, apart from the title we have headings. The heading tags are denoted with the h1, h2, h3, h4, h5, h6 tags.

Their role is to inform the visitor with summarised information about the content that’s ahead and thus help readers better understand what they are about to read.
This is also very useful for the search engines as the headings encapsulate the most important information your page and provide guidance as to keywords the page is targeted towards.
Google’s algorithm will weight the keywords and phrases of the heading tags more than the rest of the content.
Regarding the heading tags in a web page, the HTML standard request the following:
- Each page can contain one or more h1 to h6 heading tags
- Each h1 to h6 tag necessarily requires a <hn> opening tag and a </hn> closing tag where n is the heading level.
- There are 6 possible levels of heading tags: h1, h2, h3, h4, h5 and h6. h1 is a first-level heading, which is the most close tag to a document title, while the h6 tag is the most fine detail heading tag.
For successful heading composition, titles should be used in sequence. An example usage pattern would be:
|
Correct |
Correct | Wrong |
| H1
H2 H3 H4 H5 |
H1 H2 H3 H4 H2 H3 H4 H5
|
H1 H3 H2 H6 |
The first example is correct and it is quite straightforward. The second is simply the same as the first, it only shows how you can use multiple tags as long as they have the correct hierarchy.
The last example is wrong because it does not honour the correct sequence. Missing a fine grain tag is not that much of an issue as long as it contains the most important titles (h1, h2, h3).
But having them in a wrong order or leaving them without the proper parent heading is a pitfall you should avoid.
Search engines do not deal with heading tags with the same importance. The less the number that follow h, the higher the level of the heading and the higher its importance in regards to search engines.
Therefore, if your content misses an h1 or h2 tag, you miss an important part of your content definition. If you don’t use h6 but still use h1, h2 headings the condition is manageable.
Thus, focus your SEO efforts by priority on h1 heading tags, then on the h2, and then all the rest.
Page Title
Let’s take a deeper look at the titles and how they should utilise keywords. The first remark has to do with the position of the Target keyword. The more left, the better.
Starting your title with the most prominent keyword helps search engines understand the meaning quicker and rank you better from the start.
Action words. Verbs that dictate to your audience what to do. Words like learn, find, read, see, discover, or words that dictate a transaction like buy, sell, get, download, try, help not only your audience understand what to do but also search engines understand the reason of that page’s existence.
Your next movements should be to add synonyms, keyword variations and secondary keywords.
Doing this is important if you want to increase the chances of ranking on multiple search queries for different keywords than the primary. This mix and match will solidify your primary keywords and in the same time provide a differentiation that search engines can map to different cognitive aspects of a search query.
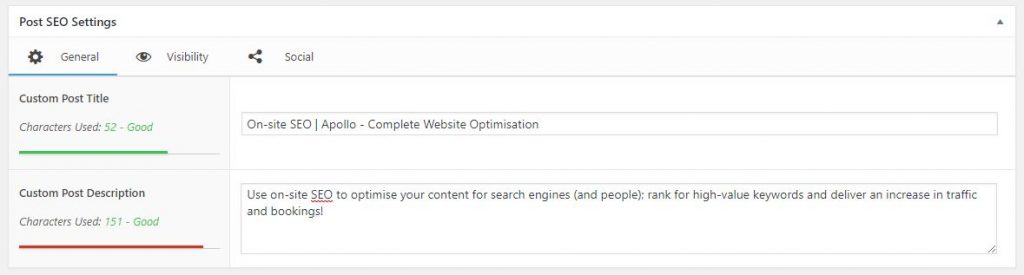
What you should avoid in your pages and especially in your titles is keyword mirroring. This situation occurs when a single term or keyword is overused in such a level that several pages have the same keyword target in the title and header tags.
This will pose problems for search engines trying to understand what page is better as a search result when all of them look alike in terms of describing the same thing, the same keywords.
When we’re talking about the title of your homepage, your most precious landing page, remember that we are referring to the page that gathers the most in authority links should have the strongest page rank.
Therefore, your homepage’s title tag should be the most powerful SEO element (most valuable target keyword) on your entire site. So this is the place that you want to insert your most competitive keywords, your signature keywords, those that are the hardest ones to rank.
What should your page title include?
Regarding the page title format use the following as best practice:
<Target keyword> | <brand name><primary brand keyword><secondary keyword>
This format is important because it makes sure that listings of your site in the search result pages remain consistent and have the same look and feel. It also enforces the same appearance of titles over large-scale content networks and multiple contributors as well as reinforcing branding through the repetition of the brand.
Great Content
…Means Usable Content
If you offer good content, people will engage with it (time on your site), share it (on Twitter and Facebook etc) and search engines will rank you higher.
Every now and then Google changes its keyword and site ranking algorithm, silently of course, but the impact is always profound.
Google’s aim is to make their algorithm more discerning when it has to compare two successive shades of the fifty shades of quality.
They want to be able to sort sites by their quality, even if the difference between each is small.
On every algorithm update, you hear about different parameters, yet one factor is common and repetitive: quality.
Quality content, quality links, quality keywords, quality etc. Build quality content by hearing the needs of the people. Observe the trends.
Use informational keywords and dress them up with resourceful, useful and detailed content.
Utilise meta descriptions, title tags, and image tags with consistency and you will see your content spread.
Social media platforms will like your content and in time the internet will honour it with relevant, high quality, and thus high page-rank links.
But what happens if you discover that a certain page on your site ranks high for a keyword that you didn’t intent to?
Why it happens
It is not a rare phenomenon to have a page-ranking better for a non-intended keyword than the intended one.
In order to diagnose the exact underlying reason, you will have to google the keywords you target using the site or the exact page scope modifier (i.e. “site examplesite.com: keyword). In other words, you should ask Google about the problem.
This will easily show you the existence of the keywords, their density and their locations, something that will give you clues about the keyword. Is it a wrong keyword selection? Irrelevant? Not the best choice? Or, on the other hand, is there something wrong with the page? Is there really a page devoted to the specific keyword?
How to cope with it
Check that the keyword has its own page. If it doesn’t you have to create it. If it exists, you have to enhance its content.
The content should not deviate from your main keyword and spread over different topics. Build internal links that will help search engines understand better the keyword relation to the content and its differences from other keywords. Do the same with external backlinks from related content.
If you have external links that come from irrelevant content then your problem is either the remote content or the remote link. In both cases, it is easier to send an e-mail to the author of the remote content to correct the link.
Be prepared to divert the old link to either existing relevant content on your site or new, high-quality content.
Further steps
Check for broken content. Does your page have the same external links as it did one or two months ago? Is there anything missing? Did you used any redirects (301’s)? Are there any other pages sharing some of the keywords?
Questions like these may help you take all the measures to correct content-keyword pairs judged by Google as dimly correlated.
Meta Data
Meet My Meta
Meta descriptions, metadata, or even simply ‘meta’ are small HTML attributes that provide concise summaries of web page content.
There commonly two ways to view them. They either appear underneath the clickable page description links in a search engine results page (aka SERPs) or you will have to use your browse in ‘inspect’ or ‘view page source’ mode to view them.
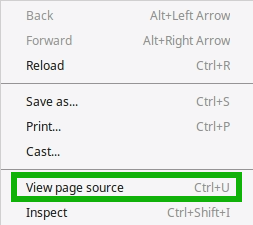
These descriptions should ideally be no more than 155 characters. The optimal is to use as much of this length as you can so that the descriptions be informative enough, but not exceed it neither formulate the text so that it reads unnaturally.
If these descriptions are of poor quality, chances are that people who see your listings in the SERPs turn to some other sites that present a more well-written description of what they’re looking for.
Don’t forget that is it an issue to have multiple or duplicate meta description tags and to have meta descriptions that aren’t unique (a common problem across many website).

Another tip for successful employment of meta tags is to avoid using double quotation marks. Google cuts off the description at the quotation mark when it appears on a SERP.
To be sure it will not happen to your meta, remove all non-alphanumeric characters.
If quotation marks are important in one or two meta descriptions for some reasons, use the appropriate HTML entity to prevent truncation.
Bear in mind that if you don’t provide a meta description, Google will create one based on the text contents of your page. So, in some cases that your page is not intended to rank high on search results it is not a big deal not to have a meta.
In the case you have a high ranking page though, it is imperative to provide a well-written meta description that captivates the users performing the search query.
Availability and Accessibility
Reliable website and hosting
Availability means that you offer content 24/7 without downtime. The selection of a reliable and fast server is a good investment.
If your server suffers downtime then your content will not be available and this can turn potential customers away from your website.
Availability also means that your content is clean from dead links. Your visitors will tend to quit after even a single instance of a dead-end or a 404 (content not found page).

Accessibility means that your content is accessible from different types of devices—desktops, tablets, mobile phones, operating systems—unix variants, windows variants, android, iOS, etc, browsers—internet explorer, chrome, opera, dolphin, etc.
Nowadays all sites are built to be responsive, that is automatically adapt on the previous diverse circumstances and deliver the content with the less friction from the user side.
If you resize the browser’s window on a desktop while viewing your site in a width say less than one third of the screens width and the browser window displays a horizontal scrollbar on the bottom, then condole yourself. Your site is not mobile responsive yet.
Site Speed
The Need for Speed
How nice it is when you don’t have to wait an age for pages to load?
Google encourages web developers to use fast servers, close to the country that they supply. They employ an army of techniques to speed things up and make the whole process of page loading as quick as possible.
Yet, many SEO gurus will argue that Google’s PageSpeed grade is not actually an accurate indicator of speed and that achieving an “A” grade is seemingly impossible.
It’s good to have a look at your sites pagespeed results (use Google Pagespeed Insights) if only to apply the Paretto rule: Fix the important 20% and you will achieve 80% better performance.
From that point on the effort that’s needed for further improvement may well not be worth it. In fact, no site gets a perfect grade.
You can remove render-blocking JavaScript by either putting it in the footer of the page, or load it asynchronously (after the page has loaded). This task may be quite hard, especially if you are using a WordPress theme off-the-shelf.
Another step to improve performance is to optimize CSS delivery. What this means is that Google wants you to split CSS into two parts, one that will be used to render the initial part page and should be put into the HTML code rather than leave it inside the main CSS pool.
That makes pages load faster because the needed styles are already there when the rendering of the page starts.
Cache
Another easy trick you can do is to use a cache directive on your server, if it allows you to do so, or otherwise a cache plugin.
Both methods ensure that the content is served from a stored version, rather than each load calling all of the information anew. This reduces load times across the site and helps with server performance.
Caching is used to provide the bots the requested pages fast. You don’t want to make bots wait in a queue, this can lead to non-indexed pages due to slow response times.
Plugins are usually small applications that you can install into your CMS platform. Either you use WordPress, Joomla, Drupal, magento or whichever CMS you choose, as long as it has the ability to use plugins.
You may use a plugin for caching your files or a plugin to turn your site into an e-shop. Use a plugin for captcha verification or for a firewall, antivirus, spam comment blocker or other security feature.
Most are free, or they have at least a free version.
Clarity
Your content will not be usable unless it is clear to the users what you want and what’s in it for them.
To achieve clarity, you must keep things simple and set the spotlight on the most important information. If you distract your visitors with too much information, they will probably get confused and leave.
Build on known information so that your audience feels familiar to your content up to a level.
Create a well-structured site where people can find what they want in the place they expect it to be. Use standard patterns in your writing (introduction, main theme, call to action) and be consistent. Don’t adopt features that spoil the user experience just because they look fancy.
Guide your visitors to your site like a tour guide. Show them what they were missing and why this site is here.
Let people interact with your site. Give them speech and feedback opportunities. Provide them with an indication that their actions were successful or not. Don’t forget to be polite and say thanks for the input.
Learnability
Your site will not be usable if it takes a long time for a user to figure out how it works.
Your user interface should adhere to common design patterns, utilise elements that are easy to use and keep a consistent look and feel site wide.
If you create something new, make sure it is self-explanatory.
Credibility
Bravo! Nice site, but is it about a real company? Is it trustworthy? Credibility is a game changer for any website.
It is essential to show people that you are a real company with real people. Provide contact information and have a prominent ‘About Us’ section. Use a postal address, a map or even a street view whenever possible to show that there is a real business behind the website.
List your site in relevant directories, such as Google Business and nationwide yellow or white pages. Use secure layer connection protocols that are appropriate for your site (https).
Relevancy
Relevancy is a coin with two sides. Inside your site the contents should be related to each other and related in specific ways to external content though references.
If you cannot achieve harmony it is better to split the content in different taxonomies, categories, subdomains or even in different domains.
The second side of the coin is your users.
Be prepared to differentiate your content based on the diverse audience you may attract.
Who are the users of your site? What are their goals when they visit your site? What type of content do they prefer?
Build content that engages your target audience and design the interface in a way that the site will be a great and easy experience for your users.
These factors are easy to grasp but not that easy to achieve, especially if you run a huge site that produces and consumes great amount of content. Yet through an incremental approach of small modifications and refinements, it is usually possible to achieve a good level of overall usability for the people who visit it.
While taking good care of the previous content aspects is important to achieve high SEO results, it also necessary to avoid pitfalls that will negatively affect your ranking. The most common error, especially for newbies, is the keyword stuffing.
Duplicate Content
Don’t panic, it’s canonical
Sometimes it so happens that repetition is unavoidable.
In this case you may have content that appears on your site or over the internet in many places, which may or may not share the same root (domain).
While strictly speaking duplicate content is not a penalty, it may still sometimes affect your ranking.
If Google realises that most of your content on your website is appreciably similar to other sources, that will be recognised and your ranking would be affected accordingly.
How do duplicate content issues arise?
In most cases, website owners create it unintentionally. Let’s review some of the ways this can occur.
URL variations
URL parameters—those little values in the URL separated by ‘&’ (…&page=1&count=10&lang=en…) — can create duplicate content.
Some cache plugins suffer from this issue as they blindly provide the same HTML page for different URLs as the request may require. This problem can get more complicated if the order of parameters changes from request to request but the target html page is the same.
HTTP vs. HTTPS or WWW vs. non-WWW pages
If your site has separate versions at ‘www.site.com’ and ‘site.com’ (with and without the “www” prefix), and the same content lives at both versions, you’ve effectively created duplicates of each of those pages.
The same applies to sites that maintain versions at both http:// and https://.
If both versions of a page are live and visible to search engines, you may run into a duplicate content issue and some versions of the page will need to be-redirected.
HTML templates for products or services
If your site is about similar products, you will probably want to use HTML templates to achieve a uniform representation.
This may lead Google to see ‘appreciably similar’ content repeatedly over the products you have in store.
In fact, if the products on your site are also sold elsewhere, perhaps both re-seller sites use the same sources for description, images and links, a classic case of duplication.
How to resolve duplicate content issues
First, make sure that you make only one version of the site available, served regardless of the existence of the URL prefix. This is a task for the .htaccess file on your root directory.
Second, make sure that no plugins or code in general on your site formulates the URL links with different parameter sequence.
Pay close attention to cache plugins that create HTML versions of every possible URL in your site. And finally, use canonical links (the HTML tag rel=”canonical”) to denote content that can be found in several URLs; one of which bears the role of ‘original’ and the others are the repetitions.
With this tag the search engines will know what version of the content they should present in the search results.
Nevertheless, wouldn’t it be better to redirect the URL of the similar content to the ‘canonical’ version? It would, at least from a search engine’s perspective.
301 re-directs
301 redirects (a.k.a. permanent redirects) despite of the difficulties and the dangers they impose, have a number of benefits.
One important element is the fact that you can divert different URLs to effective landing pages to avoid getting a penalty from Google.
When launching any new website, 301 re-directs are crucial to ensure that search engines receive guidance as to the new landing page to replace the old URL.
The truth is that monitoring and managing large amounts of 301 re-directs can be problematic. Too many re-directs can easily get out of hand and create orphan content, broken links (that point to error 404—page not found) and slow down page-load times.
A common issue with redirects is the redirect loop, where two pages redirect to each other. Browsers in such a condition stop the page loading with a declaration of ‘too many redirects’.
Google-Friendly
How to Make Your Site Crawlable
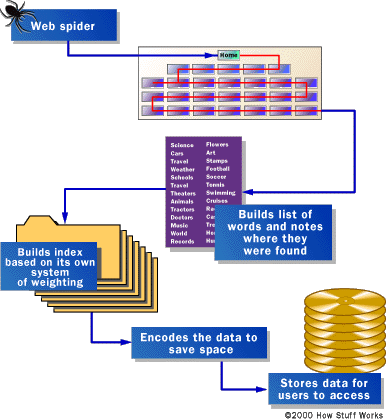
Ever wondered how Google knows everything? Bitter truth is, it doesn’t. Wikipedia does that. But Google knows where to find everything. It does so by creating indices. What is a web index?
It’s a large table of content that show search engines where to find something. This is created using two main columns: keywords and URLs.
How does Google create this database? Using software tools called spiders. Named this because they crawl the net from site to site creating a web of information.
The data retrieval that a spider follows along its path is called fetching. Google sends out millions of spiders every day to fetch information for their WWW index databases.
The first thing a web spider does when visiting a site is to look for the sitemap.xml and the robots.txt file. The latter contains directives for web crawlers whether to access a file or not. Knowing more about this file will help you avoid its improper usage, which can negatively affect your ranking. It controls how search engine spiders see and interact with your webpages.
This important role raises the significance of this file and for this reason, it is mentioned several times in Google’s search guidelines.
In order to make your site easy for the web spiders crawl, you should follow these steps:
- Create a sitemap – Use an online tool or a plugin
- Create a robots.txt file – Populate it with the desired rules including which URLs Google should not crawl
- Submit your site to search engines – Monitor the crawl results
- Create internal links – Add links between relevant pages on your site
- Build high quality content – Earn inbound links that crawlers will record
- Focus on social media marketing – Encourage social sharing
- Create a blog – Create relevant, in-depth content regularly
- Register your site to relevant directories
- Use email marketing – Develop your audience
- Create an RSS feed
- Check for indexing errors – Correct any issues found
After the steps are carried out, a ranking algorithm comes into play. This is where you reap what you sow.
Google has indexed over 90 billion pages in its database and over a trillion URLs. While this is an estimate, it is important for you to know exactly how many of them are yours and if they are indexed correctly.
Even if Google doesn’t index just one page from your site, you need to know the reason. Making your site Google-able is actually the essence of SEO.
You must try to see things from the perspective of a search engine, not just by creating text with keywords, images with alt text, etc…; but by making sure that your website is easily accessible and index-able by a search engine.
Crawling, Indexing, and Ranking
To perform well you need to remember the steps taken by a search engine: crawling, indexing, and ranking.
The first term, crawling, refers to the process of implementing a bot (or spider) to scan your site for content. It’s important to have your information structured so that a bot can easily restructure your pages.
Having good site architecture, robots.txt file and a well-written, error free XML sitemap is the most important steps towards this.
The indexing process requires the bot to fetch all your pages and scan them for raw text, keywords, meta, media, links, etc.
.Htaccess File
It is possible to use a permanent re-direct to divert traffic to a completely different server. This can be achieved on the .htaccess file level that corresponds to a specific URL directory using re-write URL rules.
Such rules inform the server that a specific URL or even a URL branch live on a different server and most probably under a different domain or sub-domain, and thus all the relevant requests should be re-routed there.
As long as you don’t deliver iterative content, Google will not have a problem with the content fragmentation.
From the server’s perspective, the less content served locally, the lighter the server load will be. For a practical example take a look at the following portion of an .htaccess file that was taken out from a modified WordPress installation.
“RewriteEngine on
RewriteCond %{HTTP_HOST}
RewriteCond %{HTTP_HOST} !^domain2\.com
RewriteRule (.*) http://www.domain1.com/$1 [R=301,L]”
The last line contains the rule that advises the server to map every request falling under the conditions described in the first two lines, actually the requests towards domain2.com and its subdomains, towards domain1.com.
In this example, the server previously responsible for serving the domain 2 files will have less of a hard time as this process is now transferred.
Sitemap
In this section, we will talk about a unique file living in the root directory of your site called sitemap.xml.
If your site is mysite.com navigate to mysite.com/sitemap.xml to view its structure and contents. If you don’t find it there, most probably you’ll need to create one.
Sitemap is an XML database file that contains the map, the structure of your site, in an easily understood manner for a web crawler.
Most modern CMS platforms like WordPress, Joomla, and others utilise many sitemaps linked together under a centralised sitemap.xml the ability to create, update and control a basic sitemap.
Advanced plugins, such as All-In-One SEO pack or Yoast SEO offer more options and fine-tuning capabilities.
Consider a site with many products, categories, portfolios, posts, reviews, and comments in many languages and you will realise the importance of a map to help search engines distinguish the full range of pages to be indexed. This file helps web crawlers be faster and more precise.
Otherwise, to locate a potential change they would need to scan all the entire file system and links, taking more time and spending more server resources on both ends, with finally the result that nothing has changed.
To help crawlers as much as possible, sitemap exhibits to the reader some special information, called metadata, this usually refers to when the page was last updated, how often the page is changed and how this page connects to other pages on the same site.
Robots.txt
In order to use a robots.txt file you firstly need to decide if you need one.
If one of the following conditions occur, you may want to consider having an active robots.txt file:
- You want specific content blocked from search engines.
- You are employing paid links or advertisements that need special handling from robots.
- You want to allow specific access to your site from selected robots.
- You are developing a site that’s live, but you don’t want crawlers to index it yet.
- It helps you follow some of Google best practices under certain conditions.
- You need some or all of the above, but do not have full access to your web-server.
On the other hand, you may want to avoid having this file manage crawlers interaction with your site because:
- It’s easier not to have one.
- You suspect that it is blocking some important pages from search engines.
- You have nothing to hide from search engines.
- You see none of the above mentioned apply in your case.
If you suspect that a robots.txt is blocking important files from the search engines, it’s a good time to perform a check with Google guidelines tool provided by varvy.com or Google Indexed Pages Checker from NorthCutt, which will notify you if you are blocking resources that Google needs to access for the content of your pages.
If you have the appropriate permissions, you can also use the Google search console to test your robots.txt file against the files indexed by its engine. Well-written instructions to do so are found here.
From there on you will acquire a full review of what is blocked and why. All you have to do next is to remove the entries you want from the file to become viewable to the web spiders.
If you want to discourage a bot from following a link use a rel=”nofollow” tag. This tag was a game changer when it first came into the SEO industry. Overnight, the google PR index of almost all sites on the net fell several grades.
Now it’s common practice for all major sites like Youtube, Facebook, CNN, Google and almost the entire internet to use this tag. Now, if you want to exclude something from index use the tag rel=”noindex”.
Examine the indexing status in the search console and if you see pages left out, locate the problem, correct it, and the re-submit a request to get them re-indexed.
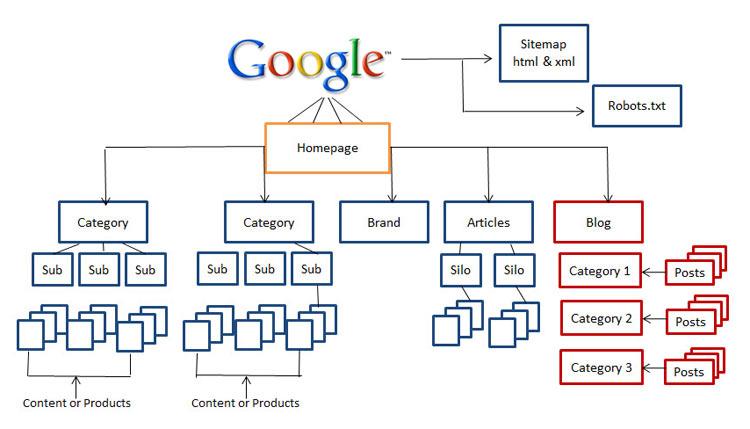
Site Hierarchy
Use a silo structure
As with all the components of a site, we want to have optimised structure of the site, so that search engines access the contents easily and can distinguish your most important pages.
We will discuss two main elements: domains and URLs. Take care of the following steps to make sure that your URL structure and the domain selection is optimised for search engines.
The ideal structure is to ensure that pages are divided into relevant sections, with your most important pages listed as ‘parent’ pages to relevant ‘children’.
Use a single domain & sub-domain
If your pages are spread across several domains or sub-domains, or a domain and some sub-domains you will have a certain ranking bleed. Search engines consider a sub-domain to be a different domain, even with regards to its parent.
That’s why if you set up a sub-domain inside a main domain you will see for one part the main domain to take a negative for the other part no equal boost to the sub-domain.
This is a well-described issue in the WordPress community where multi-site installations suffered greatly as the search engines cannot easily distinguish whether content should inherit the ranking ability of its parent domain.
The more readable, the better URLs
Do not be surprised from the fact that the easier a URL is to read for humans, the better search engine treatment it will have.
This is not just a matter of accessibility. It is how humans interact with URLs, and search engines are now able to determine what people are engaging with.
URLs have become a universal address If your URL is built up from the article id, a whole host of unique identifier codes, chances are that it will make good impression to your audience.
Keywords in URLs
Adding keywords in URLs is the correct way to go in order to achieve high ranking. It helps both your audience and the search engines to get the understand the keyword focus of your content and help you rank better.
Keywords as part of the URL structure help those who see your URL to understand where they are heading within the website. Whether they see it on social media, in an email campaign, or as they hover on a link the landing page focus will be evident to them.
In addition, sometimes URLs get striped of its anchor text. In this instance, keyword use in the URL itself plays the role of anchor text.
URLs also appear in the search results. Having a readable URL containing your target keyword the user has been looking for is a great way to get the click.
Avoid dynamic parameters in URLs
Dynamic parameters in URLs may end up in duplicate content, something we covered previously. They may end up with an unreadable or unfriendly URL format.
Further effort in this direction can be assisted by tools like mod rewrite and ISAPI rewrite or MS’ URL Rewrite Module.
Keep your URLs as short as possible
Shorter URLs are preferable than longer. Longer addresses are difficult to read and share and may point into many many folders inside the directory structure of your server’s file system.
Modern CMS’ employ a URL shortener to keep things concise.
Try to match URLs to titles
The same principles of readability apply to this point too.
Use underscores and hyphens instead of spaces and other word separators and keep them short as possible. Exact match is not required.
Exclude stop words from your URLs
Stop words (and, or, but, of, the, a, etc.), are not important in the URL Experience has proven that leaving them out will not do much harm to the URL readability.
On the opposite it will shorten a bit your URL. So it’s actually a balance between readability and address length.
Exclude punctuation characters
Special character can destroy your URL readability and they can ruin your URL structure.
If a special character comes from some exotic language or encoding you may end up with an unreachable URL
For the same reason avoid case sensitivity, unless you have a feature based on uppercase/lowercase hashes distinction.
Limit redirects to the bare minimum
You want to avoid redirection loops.
Having many 301’s increases the chances of sending your users to a black hole.
Avoid keyword stuffing
As we mentioned earlier. We do mean everywhere, including the URLs.
Other Parts of the SEO Puzzle
Anchor Text
Anchor text is called the visible, clickable blue underlined text in a hyperlink. It can provide both search engines and users textual information relevant to the content of the hyperlink’s destination.
There are several types of anchor text.
For example, anchor text may be exact-match, partial-match, branded, naked link, generic, or an image.
When the keyword of the destination page is included in the anchor text then we have ‘exact match’ anchor text. When the keyword is a variation or a synonym, we have a partial match while a branded anchor text refers to an anchor text with a brand name.
When the URL is used the anchor is a naked link. Generic anchor text is some simple generic action text like ‘Click here’.
It is important to ensure a mix of anchor text so that your anchor text profile looks as natural as possible.
HTML
HTML (Hyper Text Mark-up Language) is the standard in which web pages are produced.
It consists of text inside tags, which in turn decide the functionality and the appearance of the text. Tags may be used to insert multimedia of other webpages.
CSS
CSS (Cascading Style Sheet) is, as denoted by its name, a set of rules that provides specific rules about how and when html tags will presented.
Creating styles for web pages has the advantage of providing a consistent look and feel over the entire site.
Javascript
The Javasript is a script programming language used to control both the HTML and CSS elements.
All the animations you can see in a web page, as well as all the automations have their root in Javascript. It is not required to know Javascript to success in the SEO industry.
It helps to know the basics when it comes to identifying and locating indexing problems, loading time issues and so on.
PHP
PHP is another important programming language in the web sphere.
The vast majority of modern CMS is built upon PHP, including WordPress and Joomla. You can gain a lot if you start to learn more about this impressive programming language.
Images
Create links to images to help people and search engines find what they look for.
Use the right image, the right size, and be sure that you have the appropriate permissions to use the image for your purpose.
Do not just download image from the internet and post them on your site just because you like them. Use high-quality paid images to deliver quality results.
Make sure you have set all the right image tags in both the link and the photo.
Use pictographics to deliver captivating information.
Do not upload uncompressed, high-resolution images to the public.
Instead, use GIF, PNG, and JPEG compression for faster loading times.
Set the resolution in a level that will not degrade quality but will save your users bandwidth.
Use informative file names.
Rename the images taken from your personal camera with a descriptive, that makes it easier for search engines to related them with a topic and classify them.
Always pay attention to set the alt text descriptions.
Alternative text (aka alt text) plays the role of the identity of an image when you hover your mouse over it.
When there is a problem with the rendering of the image, alt text appears to notify the user about the image information. Moreover, it is used by screen readers to help the visually impaired perceive the contents of the image.
Create image sitemaps.
These special type sitemaps are referenced from within the main sitemap and thus consist an extension to it.
The good thing is that when there is an image update, only on small part of the sitemap is locked for update.
The other parts are free for fetching. Such sitemaps allows the indexing of the relevant images even if they get loaded inside the page by JavaScript (ie. Sliders, animations, etc).
Avoid using third-party image hosting services.
It is better to have your photos on your site. It is not uncommon for images to get deleted or change URL
Avoid a broken outbound link by using a local copy of the image.
Share your images on social media.
Social media give you the opportunity to share valuable information with others. They play a catalytic role in the overall SEO industry as well as in the customer acquisition policy.
Adding social media sharing buttons to your website, especially close to the images is perhaps the easiest way to populate your images into social media platforms.
When in doubt, ask Google.
Google’s Webmaster Guidelines are very helpful and informative regarding image publishing guidelines.
Don’t hesitate to consult these information in order to deliver high quality content to both humans and spiders.
Conclusion
All of these elements tie back to the same basic principle: creating a good user experience.
The ultimate goal of on-page SEO is to make it as easy as possible for both search engines and users to navigate your website, understand which keyword each page is targeted towards and find good-quality, engaging content.
Whilst a large part of the SEO mix relates to creating quality in-bound links, it is essential to have ticked off the boxes on-page in terms of a wide range of SEO ranking factors. On-page optimisation is always the first step in any successful SEO campaign.
Hopefully this guide has been helpful in pointing you in the right direction for where to focus your efforts.
Latest Posts
-

SEO Case Study: How to Rank for 10k MORE Organic Keywords in 4 Months!
-
How to Choose the Best SEO Agency
-
How To Choose the Best PPC Agency (And What to Ask Before You Sign)
-
SEO Case Study: 7 Steps to Increase Organic Traffic by 200%
-
Case Study: Effective SEO for a NEW Website
-
5 Tips to Get Results with Facebook Marketing
-
PPC for Travel - The Ultimate Guide for 2022
-
Using SEO Keywords To Grow Your Business
-
Top Online Marketing Strategies to Increase Bookings
-
How to Create Landing Pages Which Boost Your Bookings!
-
How To Engage Your Audience and Convert Them Into Customers
-
How to Create a Facebook Ad Account
-
Why You Need To Manage Your Businesses Online Reputation
-
10 Web-Design Tips for Travel Businesses
-
7 Digital Marketing Mistakes Travel Businesses Need to Avoid













By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.